Single image hand fitting#
In this tutorial, we demonstrate fitting of a simple hand model with simple lambertian material to a single photo.
Imports#
[1]:
import drtk
import numpy as np
import torch as th
import torch.nn.functional as thf
from IPython.display import display
from PIL import Image
import igl
from torchvision.utils import save_image
import imageio
import cv2
I1002 163544.251 _utils_internal.py:314] NCCL_DEBUG env var is set to None
I1002 163544.252 _utils_internal.py:323] NCCL_DEBUG is INFO from /etc/nccl.conf
Load obj#
[2]:
# Target vertex position
v, vt, _, vi, vti, _ = igl.read_obj("hand.obj")
width = 512
height = 512
vt = np.zeros((v.shape[0], 2), dtype=np.float32)
vti = vi.copy()
vt = th.as_tensor(vt, dtype=th.float32)[None].cuda()
vi = th.as_tensor(vi, dtype=th.int32).cuda()
vti = th.as_tensor(vti, dtype=th.int32).cuda()
v = th.as_tensor(v, dtype=th.float32)[None,].cuda()
v_initial = v.clone().detach()
Quaternian <-> matrix#
[3]:
def quaternion_to_matrix(q: th.Tensor) -> th.Tensor:
r, i, j, k = th.unbind(q, -1)
_2s = 2.0 / (q * q).sum(dim=-1)
o = th.stack(
[
1 - _2s * (j * j + k * k),
_2s * (i * j - k * r),
_2s * (i * k + j * r),
_2s * (i * j + k * r),
1 - _2s * (i * i + k * k),
_2s * (j * k - i * r),
_2s * (i * k - j * r),
_2s * (j * k + i * r),
1 - _2s * (i * i + j * j),
],
dim=-1,
)
return o.reshape(q.shape[:-1] + (3, 3))
def matrix_to_quaternion(m):
m00, m11, m22 = th.unbind(th.diagonal(m, 0, -1, -2), dim=-1)
o0 = 0.5 * (1 + m00 + m11 + m22).clamp(min=0).sqrt()
x = 0.5 * (1 + m00 - m11 - m22).clamp(min=0).sqrt()
y = 0.5 * (1 - m00 + m11 - m22).clamp(min=0).sqrt()
z = 0.5 * (1 - m00 - m11 + m22).clamp(min=0).sqrt()
o1 = x * th.sign(m[..., 2, 1] - m[..., 1, 2])
o2 = y * th.sign(m[..., 0, 2] - m[..., 2, 0])
o3 = z * th.sign(m[..., 1, 0] - m[..., 0, 1])
return th.stack((o0, o1, o2, o3), dim=-1)
Define optimizable parameters#
[4]:
v = th.nn.Parameter(v - v.mean(dim=1, keepdim=True))
t = th.nn.Parameter(th.as_tensor([0, 0, 0], dtype=th.float32)[None, ...].cuda())
r = th.as_tensor([[1, 0, 0], [0, 1, 0], [0, 0, 1]], dtype=th.float32)[None, ...].cuda()
r = th.nn.Parameter(matrix_to_quaternion(r) * 10.0)
color = th.nn.Parameter(th.tensor(np.array([0.3, 0.2, 0.15]), dtype=th.float32).cuda())
color_spec = th.nn.Parameter(
th.tensor(np.array([0.1, 0.1, 0.1]), dtype=th.float32).cuda()
)
gloss = th.nn.Parameter(th.tensor(np.array([0.3]), dtype=th.float32).cuda())
light_dir = th.nn.Parameter(
th.tensor(-np.array([0.7, 0.2, 0.8]), dtype=th.float32).cuda() * 0.1
)
light_ambient = th.nn.Parameter(
th.tensor(np.array([0.1, 0.1, 0.1]), dtype=th.float32).cuda()
)
background = th.nn.Parameter(
th.tensor(np.array([177, 161, 138]) / 255, dtype=th.float32)
.pow(2.2)
.cuda()[None, :, None, None]
.expand(-1, -1, 8, 8)
.clone()
)
Laplacian#
[5]:
def laplacian(v, vi):
vs = v[vi, :]
# Distances between every pair of vertices in each triangle
l2 = np.sum((vs[:, [1, 2, 0], :] - vs[:, [2, 0, 1], :]) ** 2, axis=2)
l = np.sqrt(l2)
# NumberOfTriangle * 3, each row in decreasing distance values.
ls = np.sort(l)[:, ::-1]
dblA = (ls[:, 0] + (ls[:, 1] + ls[:, 2])) * \
(ls[:, 2] - (ls[:, 0] - ls[:, 1])) * \
(ls[:, 2] + (ls[:, 0] - ls[:, 1])) * \
(ls[:, 0] + (ls[:, 1] - ls[:, 2]))
lap_flg = dblA <= 0
# print(f'lap_flg.sum()={lap_flg.sum()}')
dblA[dblA <= 0] = 1e-9
dblA = 2 * 0.25 * np.sqrt(dblA)
C = l2 * 0.0
C[:, 0] = (l2[:, 1] + l2[:, 2] - l2[:, 0]) / dblA[:] / 4.0
C[:, 1] = (l2[:, 2] + l2[:, 0] - l2[:, 1]) / dblA[:] / 4.0
C[:, 2] = (l2[:, 0] + l2[:, 1] - l2[:, 2]) / dblA[:] / 4.0
C[lap_flg, :] = 0
# do not materialize L matrix, instead build triples and do reduction
source = np.stack([vi[:, 1], vi[:, 2], vi[:, 0]], axis=1).reshape(-1)
dest = np.stack([vi[:, 2], vi[:, 0], vi[:, 1]], axis=1).reshape(-1)
C_flat = C.flatten()
L_indices = np.concatenate([
np.stack([source, dest], axis=1),
np.stack([dest, source], axis=1),
np.stack([source, source], axis=1),
np.stack([dest, dest], axis=1),
], axis=0)
L_values = np.concatenate([C_flat, C_flat, -C_flat, -C_flat])
# do reduction by rows
s = np.argsort(L_indices[:, 0], axis=0)
L_indices = L_indices[s, :]
L_values = L_values[s]
bins = np.bincount(L_indices[:, 0])
max_lap_count_ub = np.max(bins)
edges = np.cumsum(bins)
edges = np.concatenate([[0], edges])
lapspervert = np.zeros((v.shape[0], max_lap_count_ub), dtype=np.int32)
wlapspervert = np.zeros((v.shape[0], max_lap_count_ub), dtype=np.float32)
max_lap = 0
for e, (start, end) in enumerate(zip(edges[:-1], edges[1:])):
idx, idx_inv = np.unique(L_indices[start:end, 1], return_inverse=True)
max_lap = max(max_lap, idx.shape[0])
lapspervert[e][:idx.shape[0]] = idx
np.add.at(wlapspervert[e], idx_inv, L_values[start:end])
lapspervert = th.from_numpy(lapspervert[:, :max_lap]).long()
wlapspervert = th.from_numpy(wlapspervert[:, :max_lap])
return lapspervert, wlapspervert
[6]:
lapspervert, wlapspervert = laplacian(v[0].detach().cpu().numpy(), vi.cpu().numpy())
lapspervert = lapspervert.cuda()
wlapspervert = wlapspervert.cuda()
Load camera image of a hand#
[7]:
image_gt = (
th.as_tensor(imageio.imread("hand_image_gt.png"))
.float()
.cuda()
.permute(2, 0, 1)[None]
/ 255.0
)
save_image(image_gt, "img.png")
display(Image.open("img.png"))

Rendering#
[8]:
object_center = v.detach().mean(dim=1).cuda()
object_radius = v.detach().std(dim=1).max().cuda()
cam_t = (
object_center[0]
+ th.as_tensor([-0.07, 0.3, 1.7 * object_radius], dtype=th.float32).cuda()[None]
)
focal = th.from_numpy(np.array([[351, 0.0], [0.0, 351]], dtype=np.float32)).cuda()[None]
princpt = th.from_numpy(np.array([512 * 0.5, 512 * 0.5], dtype=np.float32)).cuda()[None]
def rodrigues(x):
x, _ = cv2.Rodrigues(np.asarray(x, dtype=np.float32))
return np.float32(x)
R = th.from_numpy(np.matmul(rodrigues([np.pi, 0, 0]), rodrigues([0, 0, 0.4]))).cuda()[
None
]
campos = (
-1
* th.bmm(R.permute(0, 2, 1).double(), cam_t[:, :, None].double())
.squeeze(-1)
.float()
.cuda()
)
[9]:
def face_normals(
v: th.Tensor, vi: th.Tensor, normalize: bool = True, eps: float = 1e-8
):
B = v.shape[0]
NF = vi.shape[0]
p = th.index_select(
v,
dim=1,
index=vi.view(
-1,
),
).view(B, NF, 3, 3)
fn = th.linalg.cross(p[:, :, 0] - p[:, :, 2], p[:, :, 1] - p[:, :, 0], dim=-1)
if normalize:
fn = thf.normalize(fn, dim=-1, eps=eps)
return fn
def face_attribute_to_vert(v: th.Tensor, vi: th.Tensor, attr: th.Tensor) -> th.Tensor:
attr = (
attr[:, :, None]
.expand(-1, -1, 3, -1)
.reshape(attr.shape[0], -1, attr.shape[-1])
)
vi_flat = vi.view(vi.shape[0], -1).expand(v.shape[0], -1)
vattr = th.zeros(v.shape[:-1], dtype=v.dtype, device=v.device)
vattr = th.stack(
[vattr.scatter_add(1, vi_flat, attr[..., i]) for i in range(attr.shape[-1])],
dim=-1,
)
return vattr
def vert_normals(
v: th.Tensor, vi: th.Tensor, normalize: bool = True, eps: float = 1e-8
):
assert vi.dtype == th.int64
# NOTE: we do not need to normalize face normals prior to re-sampling
fn = face_normals(v, vi, normalize=False)
vn = face_attribute_to_vert(v, vi[np.newaxis], fn)
if normalize:
vn = thf.normalize(vn, dim=-1, eps=eps)
return vn
[10]:
def render(
r,
t,
R,
campos,
focal,
princpt,
v,
vi,
lapspervert,
wlapspervert,
v_initial,
background,
light_dir,
light_ambient,
color,
color_spec,
gloss,
l_w,
):
rot = quaternion_to_matrix(r / 10.0).float()
geom = (rot @ v[0, :, :, None])[None, ..., 0] + t * 0.1
av3d = (R[:, None] @ (geom - campos[:, None])[..., None])[..., 0]
normals = vert_normals(av3d, vi.long())
v_pix = drtk.transform(geom, campos, R, focal, princpt)
index_img = drtk.rasterize(v_pix, vi, 512, 512)
mask = (index_img != -1)[:, None]
depth_img, bary_img = drtk.render(v_pix, vi, index_img)
vn_img = thf.normalize(
drtk.interpolate(normals, vi, index_img, bary_img.detach()), dim=1
)
light = (-vn_img * thf.normalize(light_dir[None, :, None, None], dim=1)).sum(
dim=1, keepdims=True
)
light = th.clamp(light, min=0.0) + light_ambient[None, :, None, None]
v_img = thf.normalize(drtk.interpolate(av3d, vi, index_img, bary_img), dim=1)
view_img = thf.normalize(v_img, dim=1)
h_img = thf.normalize(
thf.normalize(light_dir[None, :, None, None], dim=1) - view_img, dim=1
)
spec = (h_img * -vn_img).sum(dim=1, keepdims=True).clamp(min=1e-8) ** (
gloss[None, :, None, None] * 40
)
diff = v - v_initial
t_laplacian = (wlapspervert[None, :, :, None] * diff[:, lapspervert, :]).sum(dim=2)
laplacian_reg_loss = l_w * (t_laplacian**2).mean(dim=(1, 2))
img = mask * (
color[None, :, None, None] * light + spec * color_spec[None, :, None, None]
) + (1.0 - mask.float()) * thf.interpolate(
background, size=(512, 512), mode="bicubic"
)
img = th.pow(img.clamp(min=0.0), 1 / 2.2)
img = drtk.edge_grad_estimator(
img=img,
v_pix=v_pix,
vi=vi,
bary_img=bary_img,
index_img=index_img,
)
return img, laplacian_reg_loss, geom
Render initial scene#
[11]:
image, _, _ = render(
r,
t,
R,
campos,
focal,
princpt,
v,
vi,
lapspervert,
wlapspervert,
v_initial,
background,
light_dir,
light_ambient,
color,
color_spec,
gloss,
0.0
)
print(image.shape)
save_image(image, "img.png")
display(Image.open("img.png"))
torch.Size([1, 3, 512, 512])

Fitting#
[12]:
import av
import imageio
import IPython.display
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from tqdm import tqdm
container = av.open(
"out.mp4",
mode="w",
format="mp4",
options={"movflags": "frag_keyframe+empty_moov"},
)
video_stream = container.add_stream(
"libx264",
width=1024 + 512,
height=512,
pix_fmt="yuv420p",
framerate=24,
)
font = ImageFont.truetype("/usr/share/fonts/truetype/ttf-dejavu/DejaVuSans.ttf", 24)
loss_list = []
opt = th.optim.SGD(
[v, t, r, color, light_dir, light_ambient, background, color_spec, gloss],
lr=0.1,
)
def conv_img(x: th.Tensor) -> th.Tensor:
with th.no_grad():
x = (x * 255).type(th.long).clamp(0, 255).cpu()
if len(x.shape) == 4:
x = x[0, :, :, :]
return x.type(th.uint8).transpose(0, 2).transpose(0, 1)
def conv_img_viridis(x: th.Tensor) -> Image:
import numpy as np
import seaborn as sns
with th.no_grad():
assert x.ndim == 2
colored = (
sns.blend_palette(["#8c179a", "#64c5c2", "#fef46a"], 6, as_cmap=True)(
x.cpu().numpy().squeeze()
)[..., :-1]
* 255.0
).astype(np.uint8)
return Image.fromarray(colored)
for iter in tqdm(range(8100)):
if iter < 200:
l_w = 40
elif iter < 500:
l_w = 30
elif iter < 1000:
l_w = 16
elif iter < 2000:
l_w = 8
elif iter < 3000:
l_w = 4.0
else:
l_w = 1.0
image, laplacian_reg_loss, geom = render(
r,
t,
R,
campos,
focal,
princpt,
v,
vi,
lapspervert,
wlapspervert,
v_initial,
background,
light_dir,
light_ambient,
color,
color_spec,
gloss,
l_w,
)
# Compute loss and backpropagate
l2_error = thf.mse_loss(image, image_gt.detach(), reduction="none")
l2_loss = l2_error.mean()
loss = l2_loss + laplacian_reg_loss
loss.backward()
loss_list.append(l2_loss.item())
opt.step()
opt.zero_grad()
step = 1
if iter > 25:
step = 2
if iter > 50:
step = 4
if iter > 100:
step = 10
if iter > 200:
step = 16
if iter > 400:
step = 32
if iter > 800:
step = 64
if iter > 4000:
step = 128
if iter % step == 0:
im = th.cat([image_gt, image, th.abs(image_gt - image) / 2 + 0.5], dim=3)
u8img = conv_img(im).cpu().numpy()
container.mux(
video_stream.encode(av.VideoFrame.from_ndarray(u8img, format="rgb24"))
)
# Show the initialization state for 2 sec
if iter == 0:
for i in range(24):
container.mux(
video_stream.encode(
av.VideoFrame.from_ndarray(u8img, format="rgb24")
)
)
for i in range(24):
container.mux(
video_stream.encode(av.VideoFrame.from_ndarray(u8img, format="rgb24"))
)
# Render rotation
for iter in range(200):
with th.no_grad():
R = th.from_numpy(
np.matmul(
rodrigues([np.pi, 0, 0]), rodrigues([0, np.sin(iter / 30.0) * 0.8, 0.4])
)
).cuda()[None]
campos = (
-1
* th.bmm(R.permute(0, 2, 1).double(), 1.7 * cam_t[:, :, None].double())
.squeeze(-1)
.float()
.cuda()
)
image, _, _ = render(
r,
t,
R,
campos,
focal,
princpt,
v,
vi,
lapspervert,
wlapspervert,
v_initial,
background,
light_dir,
light_ambient,
color,
color_spec,
gloss,
l_w,
)
im = th.cat([image_gt, image, 0 * image], dim=3)
u8img = conv_img(im).cpu().numpy()
container.mux(
video_stream.encode(av.VideoFrame.from_ndarray(u8img, format="rgb24"))
)
for packet in video_stream.encode():
container.mux(packet)
container.close()
plt.plot(loss_list)
plt.show()
IPython.display.Video("out.mp4", embed=True, width=512 * 3.0, height=512)
100%|██████████| 8100/8100 [04:14<00:00, 31.80it/s]
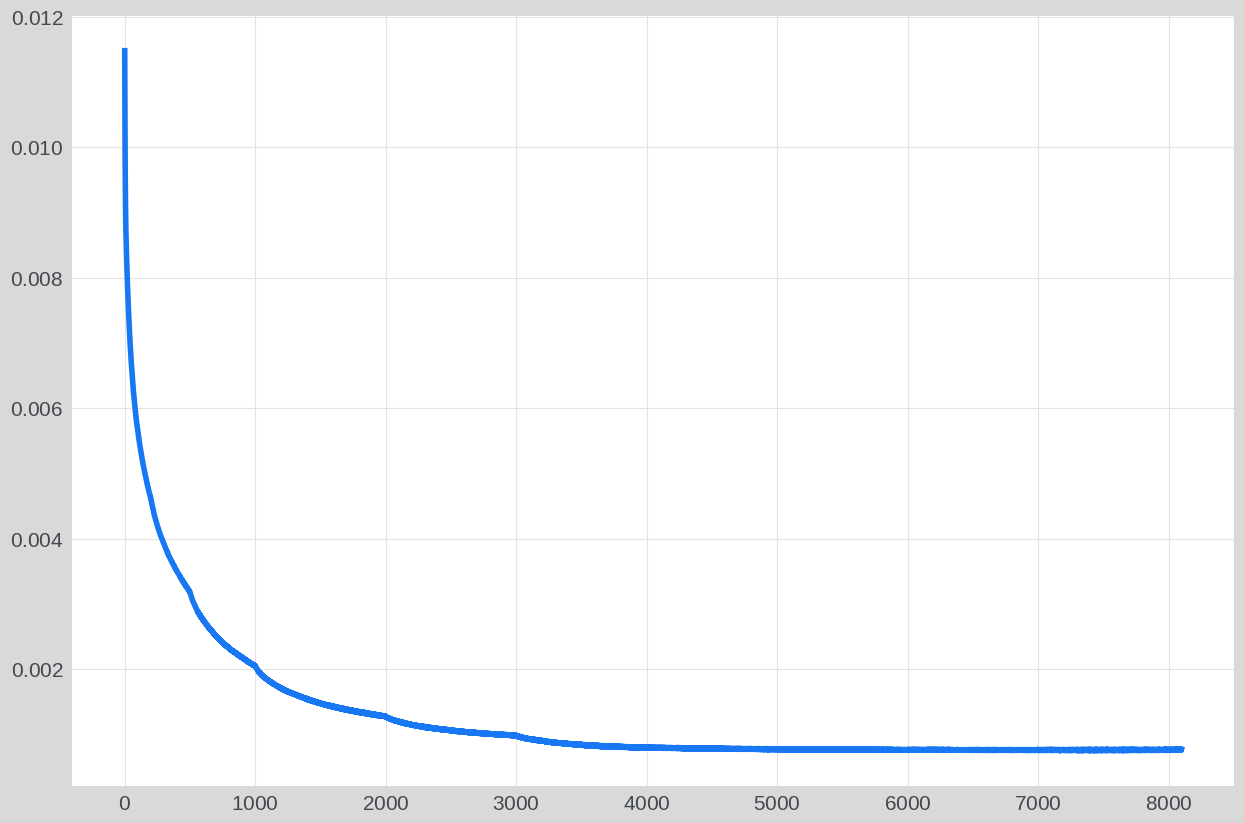
[12]: